
- 原文: Import Python Weekly Newsletter - Issue No 172
- 欢迎, 来 PyChina/weekly 共同翻译/增订/推荐 周刊 蠎消息 ;-)
该读
~ 文章, Blog, 教程...
- TensorFlow Dev Summit 2018
- TensorFlow, google
Join the TensorFlow team as they kick off the 2018 TensorFlow Dev Summit! The TensorFlow Dev Summit brings together a diverse mix of machine learning users from around the world for a full day of highly technical talks, demos, and conversations with the TensorFlow team and community.
- 如何使用 Python 中 textblob 分类器自动分配 Jira Issue?
- text classification
I’ve used Python’s textblob classifier to simply classify issues according to assignees from their description and headers. Classified issues used to classify newly created issues and results are recorded to a database. 2019 issues used as training set and %82 assignment accuracy have been achieved. As the training set grows bigger accuracy could be better.
(是也乎:
嗯哼,目测只有在客服 Issue 方向有用... )
- 基本 Python 面试题和答案
- interview questions
(是也乎:
叕一辑 FAQ.py, 应聘专用
)
- Python 开发者画像: 用什么 作什么
- survey
A survey of 9,500 developers shows what Python programmers use and what they work on. See how typical you are as a Python developer
(是也乎:
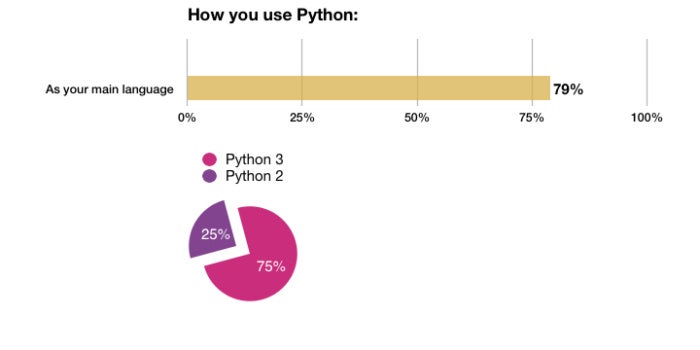
等等吧, 所以, Py2 即便官方不维护, 也不影响其广泛的使用...
)
- 最佳免费 Python 可视化包
- visualization
Nice curated list.
(是也乎:
可视化的方向一定是专业化, 通用的, 考虑到输出, 推荐 Bokeh; 考虑日常推荐: pandas 呃, 其实用的就是: matplotlib
)
- 在 Python 中回归一个比例
- statistics
I frequently predict proportions (e.g., proportion of year during which a customer is active). This is a regression task because the dependent variables is a float, but the dependent variable is bound between the 0 and 1. Googling around, I had a hard time finding the a good way to model this situation, so I’ve written here what I think is the most straight forward solution.
(是也乎:
数据归一化的常见招术式:
from sklearn.datasets import make_regression
)
- 用 Python 对非数字数据进行聚类
- numeric_data
Clustering data is the process of grouping items so that items in a group (cluster) are similar and items in different groups are dissimilar. After data has been clustered, the results can be analyzed to see if any useful patterns emerge. For example, clustered sales data could reveal which items are often purchased together (famously, beer and diapers).
- 主题建模评估: 主题一致性
- topic modeling
In this article, we will go through the evaluation of Topic Modelling by introducing the concept of Topic coherence, as topic models give no guaranty on the interpretability of their output. Topic modeling provides us with methods to organize, understand and summarize large collections of textual information. There are many techniques that are used to obtain topic models. Latent Dirichlet Allocation (LDA) is a widely used topic modeling technique to extract topic from the textual data.
PyTorch 1.0 takes the modular, production-oriented capabilities from Caffe2 and ONNX and combines them with PyTorch's existing flexible, research-focused design to provide a fast, seamless path from research prototyping to production deployment for a broad range of AI projects.
(是也乎:
江湖传说:to be politically correct at Google
import torch as tf
)
- 用 Python 基于 Google 位置记录分析通勤情况 | nvbn blog
- visualization, location, commute
Since I moved to Amsterdam I’m biking to work almost every morning. And as Google is always tracking the location of my phone, I thought that it might be interesting to do something with that data.
(是也乎:
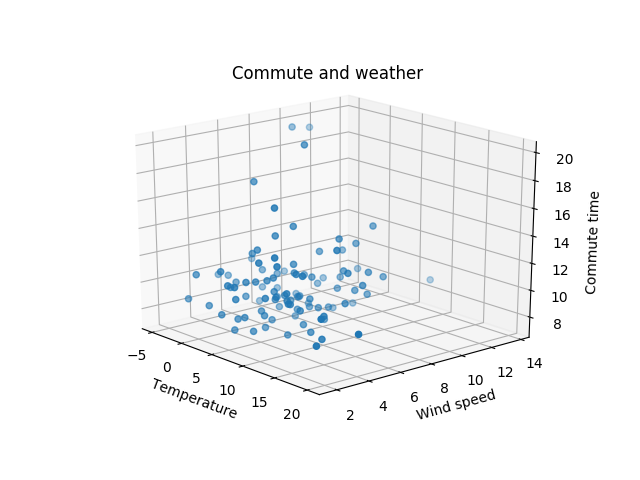
反正都被追踪了, 那么除了 google 自动分析 我们自己也应该可以...
)
- PostgreSQL: 跨函数调用共享数据
- postgres
Recently I did some PostgreSQL consulting in the Berlin area (Germany) when I stumbled over an interesting request: How can data be shared across function calls in PostgreSQL? I recalled some one of the other features of PostgreSQL (15+ years old or so) to solve the issue. Here is how it works.
(是也乎:
OpenResty 从一开始就内置了一个对象数据库来解决跨请求的数据共享/操作...
)
- 正态性测试
- testing, data science
So you have a dataset and you’re about to run some test on it but first, you need to check for normality. Think about this question, “Given my data … if there is a deviation from normality, will there be a material impact my results?”
(是也乎:
被测试数据对象集本身的正常状态检测 )
Ever just wanted to download a bunch of subtitles to check which one fits the video? Subscene got everything, but it can be tedious to download subtitles one by one.
- 前沿效益: 用 scipy 优化投资组合分配
- scipy
Given 4 assets’ risk and return as following, what could be the risk-return for any portfolio built with the assets. One may think that all possible values should fall inside the area. But it is possible to go beyond the bond, because combining inversely correlated assets can construct a portfolio with lower risk.
- Python/networkx 图形魔术
- networkx
Basic graph representation function on top of networkx graph library.
(是也乎:
networkx 是对 Graphviz 的 Pythonic 封装, 基于 dot 等工具的稳定, 可以尽情折腾...
)
- 使用 Python 和 Apache Spark 的阅读计划建议
- spark, recommendation
My goal in this post is simply to share how we at YouVersion are leveraging machine learning tools to generate product recommendations.
好物
~ 包/模块/库/片段...
- mass_archive
- 68 Stars, 11 Fork
A basic tool for pushing a web page to multiple archiving services at once.
(是也乎:
叕一个多重备份工具, 当然并不支持国内的各种云空间的...
)
- sublime_black
- 39 Stars, 0 Fork
Sublime Text package to format python code using black formatter.
(是也乎:
gfm 之后, 各种语言都开始了自己代码自动化格式化的尝试... 不过, 哈...
)
- pinboard-backup
- 5 Stars, 0 Fork
This backs up Pinboard bookmarks to DynamoDB.
(是也乎:
叕一则 AWS 生态夯实工具...
)
- pipenv-pipes
- 5 Stars, 1 Fork
Pipes - PipEnv Environment Switcher
(是也乎:
等等, 这名字越来越象 硅谷剧集那家公司的名称了....

嗯哼, 其实更加复杂了...
)
- cognises
- 4 Stars, 1 Fork
Flask Cognises: AWS Cognito group based authentication with user management
(是也乎:
AWS 叕一则专用嗯哼配置工具 )
- gsync
- 3 Stars, 0 Fork
Simple PyDrive wrapper and command line tool.
(是也乎:
首先当然是 CLI 封装为要, 否则, 自动化难以嵌入...
有总比没有的好
作者通透哪...
)
- Chinese_models_for_SpaCy
- 3 Stars, 0 Fork
Models for SpaCy that support Chinese
(是也乎:
专门用来支持 中文 的嗯哼...
)
- pyjson5
- 3 Stars, 0 Fork
A JSON5 serializer and parser library for Python 3 written in Cython.
(是也乎:
叕一发 JSON5 的嗯哼, 问题是 JSON 实在太容易崩了哪...
)
- Palette_Bot
- 3 Stars, 0 Fork
A Reddit bot that generates a color palette for images it is called upon
(是也乎:
叕一发 reddit bot 专注进行图片颜色提取, 比如说:
获得:
)
- countryinfo
- 3 Stars, 3 Fork
A python module for returning data about countries, ISO info and states/provinces within them.
(是也乎:
将国家信息整合到一个模块中以便随时可以舒服的获得....
)
- desktop-entry-creator
- 2 Stars, 1 Fork
A user-friendly GUI for creating desktop entries for installed applications on Linux
(是也乎:
Linux 桌面快捷方式的话.... 的确, 比较嗯哼, 但是, 多数也都是指向一个 CLI 工具呢
)
( ̄▽ ̄)
- TopSim: 在 Py3 中针对查询有效地搜索最相似的字符串.
- 0 Stars, 0 Fork
Search the most similar strings against the query in Python 3. State-of-the-art algorithm and data structure are adopted for best efficiency. For both flexibility and efficiency, only set-based similarities are supported right now, including Jaccard and Tversky.
(是也乎:
叕一个 Py 实现的搜索模块...当然, 对中文是否支持就不一定了
18.5.1 via: Chuancong Gao • 8 hours ago
您好,我是TopSim的作者。感谢您介绍我的Python包。TopSim从设计时就是语言无关的,所以完全支持中文。最新的更新更是优化了体验。谢谢支持。🙏
Full support of Chinese/Japanese/Korean.
$ cat test
地三鲜
红烧肉
烤全牛
木须肉
土豆炖牛肉
$ cat test | topsim-cli "牛肉" -k 3 -s tversky
土豆炖牛肉 0.666
红烧肉 0.3332
木须肉 0.3332
( ̄▽ ̄) 没毛病, 可以大力使用之 ;-)
)
30 Amazing Python Projects for the Past Year (v.2018) 其中有几个国货,也都超过 1000+星了...
<- Qix-/better-exceptions: Pretty and useful exceptions in Python, automatically. 效果惊艳...
是也乎
- 180507 Zoom.Quiet 42 分钟完成快译
- 180507 Zoom.Quiet 用时 7 分钟完成格式化.

Comments